И дело не в iSCSI. Диски подключены по Fibre Channel.
Нередко встречаю в своей деятельности, что люди, формируя кластер, предпочитают собрать два интерфейса в team, обеспечивая отказоустойчивость на физическом уровне. Само по себе это неплохо (хотя в случае каких-то проблем на сетевом уровне мы довольно часто просим его разобрать), но нередко случается, что физических интерфейсов на сервере всего два, и объединив их мы получаем один.
Дальше вдаваться в рассуждения не буду, просто приведу в качестве примера последний Post-mortem анализ: два кластера в течение почти суток штормило, судя по логам, отваливался кластерный диск, хотя сообщений о потере SAN-путей не было.
Последовательность событий, озадачивающая администратора кластера выглядела так:
Warning 140 Microsoft-Windows-Ntfs N/A
The system failed to flush data to the transaction log. Corruption may occur in VolumeId: D:, DeviceName: \Device\HarddiskVolume5. (A device which does not exist was specified.)
Warning 140 Microsoft-Windows-Ntfs N/A
The system failed to flush data to the transaction log. Corruption may occur in VolumeId: D:, DeviceName: \Device\HarddiskVolume5. (A device which does not exist was specified.)
Warning 140 Microsoft-Windows-Ntfs N/A
The system failed to flush data to the transaction log. Corruption may occur in VolumeId: D:, DeviceName: \Device\HarddiskVolume5. (An operation was attempted to a volume after it was dismounted.)
Error 1038 Microsoft-Windows-FailoverClustering Physical Disk
Resource Ownership of cluster disk ‘ClusterDisk_01’ has been unexpectedly lost by this node. Run the Validate a Configuration wizard to check your storage configuration.
Error 1069 Microsoft-Windows-FailoverClustering Resource Control Manager
Cluster resource ‘ClusterDisk_01’ of type ‘Physical Disk’ in clustered role ‘SQL Server (ClusterNode01)’ failed. Based on the failure policies for the resource and role, the cluster service may try to bring the resource online on this node or move the group to another node of the cluster and then restart it. Check the resource and group state using Failover Cluster Manager or the Get-ClusterResource Windows PowerShell cmdlet.
То есть драйвер NTFSне может записать какие-то данные на диск, а потом диск отваливается. Едва ли стоит предполагать, что второе — следствие первого, тем более оказалось, что упоминаемые в этих сообщениях диски разные.
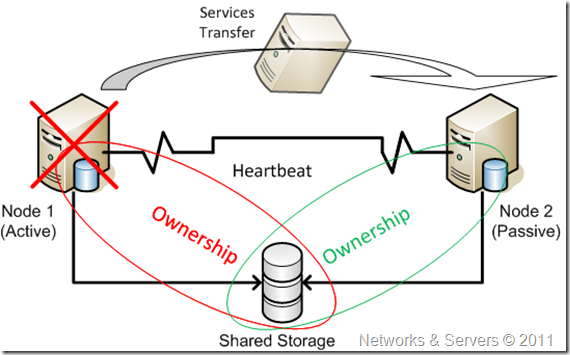
Немного о событии EventID 1038 (Ownership of cluster disk ‘…’ has been unexpectedly lost by this node. Run the Validate a Configuration wizard to check your storage configuration). Ownership нодой кластерного диска достигается путём установки специального ключа Persistent Reservation в PR-таблицу диска. Каждые 3 секунды активная нода обновляет этот ключ и удаляет чужие ключи из колонки претендентов на ownership. Если она не может обновить ключ или видит, что PR-key установлен другой нодой, появляется данное сообщение.
По результатам изучения в cluster.log выяснилось, что проблемам с дисками предшествовали следующие события:
Нода 2 (IP 10.10.12.19) потеряла связь с нодами 1 и 3 (10.10.12.18, 10.10.12.20)
16673 00000978.00002a58::2016/11/08-01:48:13.350 INFO [IM] got event: Remote endpoint 10.10.12.18:~3343~ unreachable from 10.10.12.19:~3343~
16676 00000978.00002a58::2016/11/08-01:48:13.350 INFO [IM] Marking Route from 10.10.12.19:~3343~ to 10.10.12.18:~3343~ as down
16709 00000978.00002a58::2016/11/08-01:48:13.350 INFO [IM] got event: Remote endpoint 10.10.12.20:~3343~ unreachable from 10.10.12.19:~3343~
16711 00000978.00002a58::2016/11/08-01:48:13.350 INFO [IM] Marking Route from 10.10.12.19:~3343~ to 10.10.12.20:~3343~ as down
Вскоре после этого проверка показала, что диск, которым эта нода вроде как владеет, уже кем-то используется.
17060 00000788.00003a14::2016/11/08-01:48:18.350 ERR [RES] Physical Disk <ClusterDisk_01>: IsAlive sanity check failed!, pending IO completed with status 170.
17061 00000788.00003a14::2016/11/08-01:48:18.350 ERR [RES] Physical Disk <ClusterDisk_01>: IsAlive sanity check failed!, pending IO completed with status 170.
>net helpmsg 170
The requested resource is in use.
Ну и ожидаемый результат:
17066 00000788.00003a14::2016/11/08-01:48:18.350 WARN [RHS] Resource ClusterDisk_01 IsAlive has indicated failure.
17107 00000e18.00003490::2016/11/08-01:48:18.350 WARN [RHS] returning ResourceExitStateTerminate.
17167 000012b0.00000e4c::2016/11/08-01:48:18.881 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Описанным выше событиям предшествовало большое количество записей о проблемах доступности нод друг до друга в течение нескольких часов (более четырёх, возможно было и больше, но лог начался с момента за 4 часа до инцидента). Примерно так это выглядит:
15155 00000978.00001730::2016/11/08-01:10:02.534 ERR [NODE] Node 3: channel (write) to node 2 is broken. Reason GracefulClose(1226)’ because of ‘channel to remote endpoint fe80::f87b:1c23:2502:f20c%12:~62689~ is closed’
16645 00000978.000009d8::2016/11/08-01:48:13.346 ERR [NODE] Node 3: channel (write) to node 1 is broken. Reason GracefulClose(1226)’ because of ‘channel to remote endpoint fe80::571:78af:b8e2:c4d3%12:~53853~ is closed’
16646 00000978.00001730::2016/11/08-01:48:13.346 ERR [NODE] Node 3: channel (write) to node 2 is broken. Reason GracefulClose(1226)’ because of ‘channel to remote endpoint fe80::f87b:1c23:2502:f20c%12:~62710~ is closed’
16651 00000978.000027c4::2016/11/08-01:48:13.346 ERR [NODE] Node 3: Connection to Node 1 is broken. Reason Closed(1236)’ because of ‘channel to remote endpoint fe80::571:78af:b8e2:c4d3%12:~53853~ has failed with status (10054)’
16652 00000978.00003a58::2016/11/08-01:48:13.346 ERR [NODE] Node 3: Connection to Node 2 is broken. Reason Closed(1236)’ because of ‘channel to remote endpoint fe80::f87b:1c23:2502:f20c%12:~62710~ has failed with status (10054)’
Краткий итог по результатам диагностики и расследования:
- имели место сетевые проблемы, ноды регулярно теряли друг друга;
- т.к. у нас 3 ноды и 1 witness, даже с динамическим majority в условиях нестабильного сетевого соединения есть вероятность возникновения partitioning или split brain (node+node и node+withess);
- в случае, если partition считает себя кластером, а второй partition недоступен, первый пытается взять на себя нагрузку и ресурсы, в т.ч. «захватить» диски;
- активная нода обнаруживает, что диск используется другим сервером и теряет ownership.
- Сервис падает.
А вот если бы каждая нода имела не один сетевой интерфейс, а три, как положено: межкластерное взаимодействие, менеджмент и клиентский доступ, то с большой долей вероятности такого бы не случилось. Потому что пока сосед доступен хотя бы по одному каналу (а хартбиты ходят по всем трём), он считается живым.
Подробнее о конфигурации сети кластера: https://blogs.technet.microsoft.com/askcore/2014/02/19/configuring-windows-failover-cluster-networks/
P.S.: все имена и IP-адреса вымышлены, все совпадения случайны.